 题目内容
(请给出正确答案)
题目内容
(请给出正确答案)
[单选题]
假设在庞大的数据集上使用Logistic回归模型,可能遇到一个问题,Logistic回归需要很长时间才能训练,如果对相同的数据进行逻辑回归,如何花费更少的时间,并给出比较相似的精度()。
A.降低学习率,减少迭代次数
B.降低学习率,增加迭代次数
C.提高学习率,增加迭代次数
D.增加学习率,减少迭代次数
查看答案

 如果结果不匹配,请 联系老师 获取答案
题目内容
(请给出正确答案)
如果结果不匹配,请 联系老师 获取答案
题目内容
(请给出正确答案)
A.降低学习率,减少迭代次数
B.降低学习率,增加迭代次数
C.提高学习率,增加迭代次数
D.增加学习率,减少迭代次数
如果结果不匹配,请 联系老师 获取答案
 更多“假设在庞大的数据集上使用Logistic回归模型,可能遇到一…”相关的问题
更多“假设在庞大的数据集上使用Logistic回归模型,可能遇到一…”相关的问题
A.对训练集随机采样,在随机采样的数据上建立模型
B.尝试使用在线机器学习算法
C.使用PCA算法减少特征维度
A.使用前向特征选择方法
B.使用后向特征排除方法
C.我们先把所有特征都使用,去训练一个模型,得到测试集上的表现.然后我们去掉一个特征,再去训练,用交叉验证看看测试集上的表现.如果表现比原来还要好,我们可以去除这个特征
D.查看相关性表,去除相关性最高的一些特征
A.朴素贝叶斯(NaiveBayes,NB)
B.Logistic回归(LogisticRegression,LR)
C.支持向量机(SupportVectorMachine,SVM)
D.决策树(DecisionTree,DT)
参考4.4节中所用的例子。你将使用数据集TWOYEAR.RAW.
(i)变量phsrank表示一个人的高中百分位等级。(数字越大越好。比如90意味着, 你的排名比所在班级中90%的同学更高。)求出样本中phsrank的最小、最大和平均值。
(ii)在方程(4.26) 中增加变量phsrank, 并照常报告OLS估计值。phs rank在统计上显著吗?高中排名提高10个百分位点,能导致工资增加多少?
(iii)在方程(4.26) 中增加变量phs rank显著改变了2年制和4年制大学教育回报的结论了吗?请解释。
(iv)数据集包含了一个被称为id的变量。你若在方程(4.17)或(4.26)中增加id,预计它在统计上不会显著,解释为什么?双侧检验的p值是多少?
ize) 方面的信息, 以及参与美国个人的特定养老金计划方面的信息。财富和收入变量都以千美元为单位记录。对于这里的问题, 只使用单身者数据(fsize=1)。
(i)数据集中有多少单身者?
(il)利用OLS估计模型
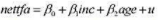
并以常用格式报告结果。解释斜率系数。斜率估计值有何惊人之处吗?
(iii)第(ii)部分的回归截距有重要意义吗?请解释。
(iv)在1%的显著性水平上,针对H1:β2<1检验H0:β2=1,求出p值。你能拒绝H0吗?
(V)如果你做一个nettfa对inc的简单回归, inc的斜率估计值与第(ii) 部分的估计值有很大不同吗?为什么?

















