

 如果结果不匹配,请
如果结果不匹配,请 
 更多“证明本节中关于问题与的最优解之间的对应关系的结论.”相关的问题
更多“证明本节中关于问题与的最优解之间的对应关系的结论.”相关的问题
A.原问题和对偶问题最优值相等时各自取得最优解,最优解相等
B.对偶问题的解其实是对应资源的影子价格
C.原问题有最优解,对偶问题一定有最优解
D.原问题和对偶问题互为对偶
A.有无穷多个最优解
B.有有限个最优解
C.有唯一的最优解
D.无最优解
对下述线性规划问题:
max z=x1-x2+x3-x4
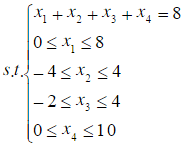
应用互补松弛定理,证明x1=8,x2=-4,x3=4,x4=0是此问题的最优解。
A.两个可行解对应的目标函数值相等
B.两个问题都有最优解
C.两个问题的最优值相等
D.原问题任一可行解的目标函数值不超过对偶问题某可行解目标函数值
对于约束条件的常数项含参数的线性规划问题,得出最优区间
A.贪心算法所做出的选择只是在某种意义上的局部最优选择。
B.贪心算法并不从整体最优考虑。
C.贪心算法无法求得问题的最优解。
D.贪心算法的时间效率最高。
E.选择能产生问题最优解的最优量度标准是使用贪婪算法的核心。
运用多元函数条件极值理论推证:若xu是障碍问题(Pu)的最优解,则xu除满足Axu=b外,还满足
wuxu-nu其中,wu=c-uuA,uu是Lagrange乘子向量.并证明:xu和(uu,wu)分别是LP和DP的可行解,且对偶间隙
cxu-uub=wuxu→0(u→0+).
A.可行解中包含基可行解
B.可行解与基本解之间无交集
C.线性规划问题有可行解必有基可行解
D.满足非负约束条件的基本解为基可行解
A.当优化问题的数值解接近局部最优值时,随着目标函数解的梯度接近或变为零,通过最终迭代获得的数值解可能仅使目标函数局部最优,而不是全局最优
B.在深度学习优化问题中,经常遇到的是梯度爆炸或梯度消失
C.优化问题中设置的学习率决定目标函数能否收敛到局部最小值,以及何时收敛到最小值
D.一般来说,小批量随机梯度下降比随机梯度下降和梯度下降的速度慢,收敛风险较大
















