 题目内容
(请给出正确答案)
题目内容
(请给出正确答案)
[单选题]
回归分析中,对于被解释变量如果是分类变量,则应采用()。
A.线性回归分析
B.曲线估计
C.逻辑回归
D.以上都不对
查看答案

 如果结果不匹配,请 联系老师 获取答案
题目内容
(请给出正确答案)
如果结果不匹配,请 联系老师 获取答案
题目内容
(请给出正确答案)
A.线性回归分析
B.曲线估计
C.逻辑回归
D.以上都不对
如果结果不匹配,请 联系老师 获取答案
 更多“回归分析中,对于被解释变量如果是分类变量,则应采用( )。”相关的问题
更多“回归分析中,对于被解释变量如果是分类变量,则应采用( )。”相关的问题
A、被解释变量的观测值Y与其平均值的离差平方和
B、被解释变量的回归值与其平均值的离差平方和
C、被解释变量的总体离差平方和与残差平方和之差
D、解释变量变动所引起的被解释变量变动的离差的大小
E、随机因素影响所引起的被解释变量的离差大小
A.在解释变量给定值下,被解释变量总体均值的轨迹
B.在解释变量给定值下,被解释变量个值得轨迹
C.在解释变量给定值下,被解释变量样本均值的轨迹
D.在解释变量给定值下,被解释变量样本个值得轨迹
利用WAGEPAN中数据。
(i)利用混合最小二乘法(pooledOLS)估计一个log(ag为被解释变量的方程。以educ,black,exper,married,union以及一系列时间虚拟变量(以1980年为基年)为可解释变量,解释及讨论变量married和union的系数。
(ii)解释为什么通常(i)中标准误总是偏小。算出关于married和union两个变量对自相关和异方差一稳健的标准误。
(iii)现在对变量lwage,exper,married和union进行一阶差分。(不随时间改变的变量educ,black和hisp被排除在这个估计之外,exper也是,因为它总是随着年份增加。)注意排除首年即1980年的一阶差分,因为不存在更早的年份。
(iv)就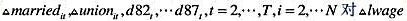 作回归分析,确保包括一个常数项和一个从1982年到1987年的时间虚拟变量。算出Δmarried和Δunion的系数和标准误。
作回归分析,确保包括一个常数项和一个从1982年到1987年的时间虚拟变量。算出Δmarried和Δunion的系数和标准误。
(v)对比婚姻状况和工会保费的估计水平及其一阶差分估计,并作相应评论。
(i)加州的安全带法规在何年何月生效?高速公路上的限速何时提高到每小时65英里。
(ii)将变量log(1otacc)对一个线性时间趋势和11个月度虚拟变量(1月作为基期)进行回归。解释时间趋势变量的系数估计值。你认为交通事故总数中存在季节性吗?
(iii)在第(ii)部分的回归中添加变量wkends,unem,spdlaw和belilw。讨论失业变量系数。你认为它的符号和大小合理吗?
(iv)在第(iii)部分的回归中,解释spdlw和beltlaw的系数。估计的影响如你所料吗?请解释。
(v)变量prefar是至少导致1人死亡的交通事故百分数。注意这个变量是一个百分数,而不是比例。在此期间prefar的平均值是多少?其大小看来正确吗?
(vi)用prcfat而非log(totacc)作为因变量重做第(ii)部分的回归。讨论最高限速和安全带法规变量的估计效应和显著性。
在EG检验的第二步中,如果均衡误差是稳定序列,则认为()。
A.被解释变量和解释变量为(1,1)阶协整
B.被解释变量和解释变量为平稳的
C.被解释变量和解释变量为(2,1)阶协整
D.被解释变量和解释变量为(1,2)阶协整
数据。变量gwage232是232部门平均工资的月增长率(以对数形式变化),getup232是232部门的就业增长率,gmwage是联邦最低工资的增长率,而gcpi是(城市)消费者价格指数的增长率。
(i)将变量gwage232对gmwage和gCPI进行回归。你认为βgmwage的符号和大小合理吗?请加以解释。gmwage在统计上显著吗?
(ii)在第(i)部分的方程中增加gmwage的1至12阶滞后变量。为了估计第232部门中最低工资的增加对平均工资增长率的长期影响,你认为有必要包括这些滞后变量吗?请加以解释。
(iii)将变量getup232对gmwage和gcpi进行回归。最低工资增长看起来对同期的getup232有影响吗?
(iv)在就业增长方程中增加gmwage的1至12阶滞后变量。在短期或长期中,最低工资的提高对就业增长具有统计显著的影响吗?请加以解释。
(i)变量train是工作培训指标变量。样本中有多少人参与了工作培训项目?一个男人实际参加工作培训最多达几个月?
(ii)将train对unem74,unem75,age,educ,black,hisp和married等几个人口统计和培训前变量做一个线性回归。这些变量在5%的显著性水平上联合显著吗?
(iii)估计第(ii)部分中线性模型的一个概率单位形式。计算所有变量联合显著性的似然比检验。你得到什么结论?
(iv)基于第(ii)部分和第(iii)部分的答案,为解释1978年的失业状况,参与工作培训可视为外生变量吗?请解释。
(v)做unem78对train的简单回归,并以方程形式报告结果。估计参与工作培训项目对1978年失业的概率有何影响?它统计显著吗?
(vi)做unem78对train的概率单位模型。将train的概率单位系数与第(v)部分线性模型中得到的系数相比较有意义吗?
(vii)求出第(v)部分与第(vi)部分的拟合概率。解释它们为什么相同。为了度量工作培训项目的效果和统计显著性,你将采用哪个方法?
(viii)在第(v)部分与第(vi)部分模型中将第(ii)部分中的所有变量作为额外控制变量。现在拟合概率还相同吗?它们之间有何关系?
(i)利用表13-1中同样的变量估计kids的一个泊松回归模型。解释y82的系数。
(ii)保持其他因素不变,黑人妇女和非黑人妇女在生育上的估计百分数差异是多少?
(iii)求σ。有过度散布和散布不足的证据吗?
(iv)计算泊松回归中的拟合值和作为kidsi和kidsi之相关系数平方的R2。并与线性回归模型中的R2相比较。
ize) 方面的信息, 以及参与美国个人的特定养老金计划方面的信息。财富和收入变量都以千美元为单位记录。对于这里的问题, 只使用单身者数据(fsize=1)。
(i)数据集中有多少单身者?
(il)利用OLS估计模型
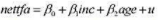
并以常用格式报告结果。解释斜率系数。斜率估计值有何惊人之处吗?
(iii)第(ii)部分的回归截距有重要意义吗?请解释。
(iv)在1%的显著性水平上,针对H1:β2<1检验H0:β2=1,求出p值。你能拒绝H0吗?
(V)如果你做一个nettfa对inc的简单回归, inc的斜率估计值与第(ii) 部分的估计值有很大不同吗?为什么?
A.为了便于确定模型的解释变量
B.为了使估计的参数具有良好的统计性质
C.为了便于确定所估计参数的均值
D.为了便于得出模型参数的估计值

















