 题目内容
(请给出正确答案)
题目内容
(请给出正确答案)
[单选题]
在Excel中,假设B1、B2、C1、C2单元格中分别存放1、2、6、9,SUM(B1:C2)和AVERAGE(B1:C2)的值等于()。
A.10,4.5
B.10,10
C.18,4.5
D.18,10
查看答案

 如果结果不匹配,请 联系老师 获取答案
题目内容
(请给出正确答案)
如果结果不匹配,请 联系老师 获取答案
题目内容
(请给出正确答案)
A.10,4.5
B.10,10
C.18,4.5
D.18,10
如果结果不匹配,请 联系老师 获取答案
 更多“在Excel中,假设B1、B2、C1、C2单元格中分别存放1…”相关的问题
更多“在Excel中,假设B1、B2、C1、C2单元格中分别存放1…”相关的问题
已知α=(a1,a2,a3),β=(b1,b2,b3),y=(c1,c2,c3),证明(α×β)·γ=-(γ×β)·α.
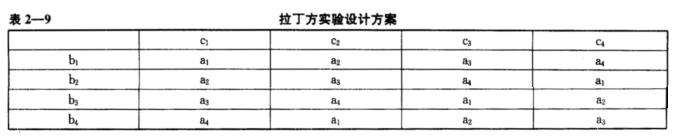
有人说表2—9所示的拉丁方实验设计的目的主要是为了研究自变量A(分别处在a1、a2、a3和a4水平)对因变量的影响,自变量B(分别处在b1、b2、b3和b4水平)和自变量C(分别处在c1、c2、c3和c4水平)处于次要地位。这种说法对吗?为什么?
现有某个应用,涉及到两个实体集,相关的属性为:
实体集R(A#,A1,A2,A3),其中A#为码
实体集S(B#,B1,B2),其中B#为码
从实体集R到S存在多对一的联系,联系属性是D1。
(1)设计相应的关系数据模型;
(2)如果将上述应用的数据库设计为一个关系模式,如下:
RS(A#,A1,A2,A3,B#,B1,B2,D1),指出该关系模式的码。
(3)假设上述关系模式RS上的全部函数依赖为:A1→A3,指出上述模式RS最高满足第几范式?(在1NF~BCNF之内)为什么?
在一个压力容器中生产某种化学产品.研究因子对产品过滤速度的影响这里有4个因子:温度(A)、压力(B)、反应物的浓度(C)、搅拌速度(D).每个因子取2个水平,每种因子水平的组合做一次试验,得到的数据列于表2.2.10中.试分析各因子及两两交互作用对试验的影响.
表2.2.10试验数据表
| A0 | A1 | |||||||
| B0 | B1 | B0 | B1 | |||||
| C0 | C1 | C0 | C1 | C0 | C1 | C0 | C1 | |
| D0 D1 | 45 43 | 68 75 | 48 45 | 80 70 | 71 100 | 60 86 | 65 104 | 65 96 |
A.=SUM(A1:A3)
B.=SUM(B1:B3)
C.=SUM(A1:B3)
D.=SUM(D1:D3)

















