 题目内容
(请给出正确答案)
题目内容
(请给出正确答案)
[单选题]
题目如果对相同的数据进行逻辑回归,将花费更少的时间,并给出比较相似的精度(也可能不一样),怎么办假设在庞大的数据集上使用Logistic回归模型。可能遇到一个问题,Logistic回归需要很长时间才能训练()
A.降低学习率,减少迭代次数
B.降低学习率,增加迭代次数
C.提高学习率,增加迭代次数
D.增加学习率,减少迭代次数
 答案
答案
D、增加学习率,减少迭代次数
 如果结果不匹配,请 联系老师 获取答案
题目内容
(请给出正确答案)
如果结果不匹配,请 联系老师 获取答案
题目内容
(请给出正确答案)
A.降低学习率,减少迭代次数
B.降低学习率,增加迭代次数
C.提高学习率,增加迭代次数
D.增加学习率,减少迭代次数
答案
D、增加学习率,减少迭代次数
如果结果不匹配,请 联系老师 获取答案
 更多“题目如果对相同的数据进行逻辑回归,将花费更少的时间,并给出比…”相关的问题
更多“题目如果对相同的数据进行逻辑回归,将花费更少的时间,并给出比…”相关的问题
A.降低学习率,减少迭代次数
B.降低学习率,增加迭代次数
C.提高学习率,增加迭代次数
D.增加学习率,减少迭代次数
A.聚类
B.决策树
C.逻辑回归
D.线性回归
在10.3节酶促反应中,如果用指数增长模型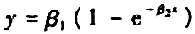 代替Michals-Menten模型对经过嘌呤霉素处理的实验数据作非线性回归分析.其结果将如何?更进一步,若选用模型
代替Michals-Menten模型对经过嘌呤霉素处理的实验数据作非线性回归分析.其结果将如何?更进一步,若选用模型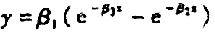 来拟合相同的数据,其结果是否比指数增长模型有所改进?试作出模型的残差图进行比较。
来拟合相同的数据,其结果是否比指数增长模型有所改进?试作出模型的残差图进行比较。
(i)求出样本中的平均工资和平均IQ。IQ的样本标准差是多少?(总体中的IQ已标准化为平均值是100,标准差是15。)
(ii)估计一个简单回归模型,其中IQ提高一个单位导致wage变化相同的数量。利用这个模型计算IQ提高15个单位时,工资的预期变化。10能够解释大多数工资波动吗?
(iii)现在再估计一个模型,其中IQ提高一个单位对工资具有相同的百分比影响。如果IQ提高15个单位,预期工资提高的百分比大约是多少?
A.逻辑回归模型
B.不带核的支持向量机
C.高斯核的支持向量机
D.多项式核的支持向量机
A.HDFSErasureCoding针对hdfs目录进行设置,可根据不同目录重要级别用途设置不同EC策略或不设置EC策略
B.现有目录上设置EC策略不会影响群集中的现有数据
C.提高HDFS存储效率,同时可以提供与基于副本相同水平的容错能力和数据持久性
D.EC策略将忽略逻辑机架感应设置,数据单元和校验单元不会按逻辑机架感应的逻辑来存储
本题需要使用ELEM 94-95中的数据, 也可参见计算机习题C 4.10。
(i) 利用所有数据, 将lavg sal对bs, lenrol, Istaff和lunch进行回归。报告bs的系数及其常用标准误和异方差-稳健标准误。你对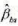 的经济显著性和统计显著性得到什么结论?
的经济显著性和统计显著性得到什么结论?
(ii)现在去掉四个bs>0.5的观测,即平均福利(假设)占平均薪水50%以上的观测。bs的系数又是多少?利用异方差-稳健标准误来判断,它在统计上显著吗?
(iii)验证bs>0.5的四个观测分别为68、1127、1508和1670。为它们各定义一个虚拟变量。(你可以称它们为d68、d1127、d 1508和d 1670.) 把它们添加到第(i) 部分的回归中, 验证其他变量的OLS系数及其标准
误与第(ii)部分中的结果相同。在5%的显著性水平上,这四个虚拟变量中哪个变量的t统计量在统计上显著不等于0?
(iv)在这个数据集中,验证第(iii)部分回归中具有最大学生化残差(该虚拟变量的t统计量最大)的数据点对OLS估计值具有很大的影响。(即利用除去具有最大学生化残差的数据点之外的所有观测进行OLS回归。)依次去掉bs>0.5的每个观测都具有重要影响吗?
(v) 即便在大样本中, 就OLS对单个观测的敏感性而言, 你有何结论?
(vi) 在第(iji) 部分, 验证LAD估计量对包含这些观测不是很敏感。
A.特征X1很可能被排除在模型之外
B.特征X1很可能还包含在模型之中
C.无法确定特征X1是否被舍
D.以上答案都不正确
使用PHILLIPS.RAW中的数据。
(i)教材例11.5中,我们估计了如下形式的附加预期的菲利普斯曲线:
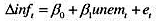
其中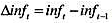 。用OLS估计该方程时,我们假定供给冲击et与unemt不相关。如果这是错误的,关于βt的OLS估计量可做什么解释?
。用OLS估计该方程时,我们假定供给冲击et与unemt不相关。如果这是错误的,关于βt的OLS估计量可做什么解释?
(ii)假定et在给定所有过去信息的条件下是不可预期的:
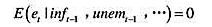
解释为什么这使得unemt-1成为unemt的一个好的Ⅳ候选者。
(iii)将unemt对unemt-1做回归。unemt与unemt-1是否显著相关?
(iv)用Ⅳ估计附加预期的菲利普斯曲线。以通常形式报告结果,并将之与教材例11.5中的OLS估计值进行比较。
A.不做任何处理,直接透传
B.去掉该数据帧的802.1Qtag标签
C.将数据帧中的VID与端口的PVID相比较,如果不相同,会删除该数据帧中的VID,如果相同,则直接透传
D.将数据帧中的VID与本端口的PVID进行比较,如果相同,就剥离掉数据帧中的VID,如果不同,就直除透传

















