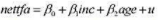题目内容
(请给出正确答案)
题目内容
(请给出正确答案)
[主观题]
(i)利用NYSE.RAW中的数据估计方程(12.48)。令h表示这个方程的拟合值(条件方差的估计值) 。有多少
(i)利用NYSE.RAW中的数据估计方程(12.48)。令h表示这个方程的拟合值(条件方差的估计值) 。有多少
个h是负的?
(ii)在式(12.48)中增加returnt-12然后再计算拟合值ht存在负的ht吗?
(iii)利用第(ii)部分得到的ht用加权最小二乘法(像在8.4节中那样)估计式(12.47)。将民的估计值与方程(11.16)中的对应结果进行比较。
(iv)现在用WLS估计方程(12.47),并用式(12.51)中估计的ARCH模型求出ht。这时, 你的结果与(iii)中的结果是否相同?
查看答案

 如果结果不匹配,请 联系老师 获取答案
如果结果不匹配,请 联系老师 获取答案

 更多“(i)利用NYSE.RAW中的数据估计方程(12.48)。令…”相关的问题
更多“(i)利用NYSE.RAW中的数据估计方程(12.48)。令…”相关的问题
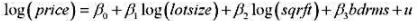
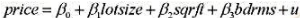

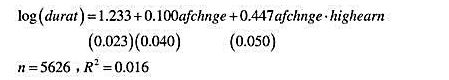
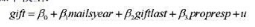
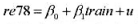 并用常用格式报告结论。基于这个回归,1976年和1977年的工作培训看上去对1978年的真实劳动工资有正的影响吗?
并用常用格式报告结论。基于这个回归,1976年和1977年的工作培训看上去对1978年的真实劳动工资有正的影响吗?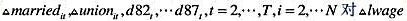 作回归分析,确保包括一个常数项和一个从1982年到1987年的时间虚拟变量。算出Δmarried和Δunion的系数和标准误。
作回归分析,确保包括一个常数项和一个从1982年到1987年的时间虚拟变量。算出Δmarried和Δunion的系数和标准误。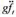 。
。 。
。 对教材方程(10.35)中所有变量(包括t和t2)回归。比较得出的R²与教材方程(10.35)中的R2有何不同。你有何结论?
对教材方程(10.35)中所有变量(包括t和t2)回归。比较得出的R²与教材方程(10.35)中的R2有何不同。你有何结论?