
 如果结果不匹配,请
如果结果不匹配,请 
 更多“当模型中第i个方程是不可识别的,那么该模型是()。”相关的问题
更多“当模型中第i个方程是不可识别的,那么该模型是()。”相关的问题
一个由两个方程组成的联立模型的结构形式如下(省略t-下标)
Pt=α0+α1Nt+α2St+α3At+ut
Nt=β0+β1Pt+β2Mt+vt
(1)指出该联立模型中的内生变量与外生变量。(2)分析每一个方程是否为不可识别的,过度识别的或恰好识别的?
在例10.4中我们把明显包括长期倾向θ0的模型写成,
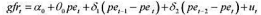
为简单起见,我们省略了其他解释变量。像通常的多元回归分析一样,θ0应该具有其他情况不变的解释。也就是说, 保持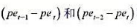 不变, 若pet增加一美元,则gfrt应该改变θ0。
不变, 若pet增加一美元,则gfrt应该改变θ0。
(i)若保持不变,但pet增加,那么pet-1和pet-2应该如何变化?
(ii)第(i)部分中的答案如何有助于你把上述方程中的θ0理解为LRP。
)序列相关。
(ii)如果你发现有序列相关的证据,用科克伦-奥卡特方法重新估计这个方程,并将所得结果与以前的结果进行比较。
相关。
(ii)如果你发现有序列相关的证据,用科克伦-奥卡特方法重新估计这个方程,并将所得结果与以前的结果进行比较。
利用PHILLIPS.RAW中的数据。
(i)估计失业率的AR(1)模型。用这个方程预测2004年的失业率。将它与2004年的实际失业率进行比较。(你可以从近年的《总统经济报告》中找到这个数据。)
(ii)在第(i)部分的方程中增加通货膨胀的一期滞后。inft-1统计上显著吗?
(iii)利用第(ii)部分中的方程预测2004年的失业率。这个结果比第(i)部分的结果更好还是更糟?
(iv)利用教材6.4节中的方法构造2004年失业率的一个95%的置信区间。2004年的实际失业率位于这个区间内吗?
个h是负的?
(ii)在式(12.48)中增加returnt-12然后再计算拟合值ht存在负的ht吗?
(iii)利用第(ii)部分得到的ht用加权最小二乘法(像在8.4节中那样)估计式(12.47)。将民的估计值与方程(11.16)中的对应结果进行比较。
(iv)现在用WLS估计方程(12.47),并用式(12.51)中估计的ARCH模型求出ht。这时, 你的结果与(iii)中的结果是否相同?
本题要利用LAWS CH 85.RAW中的数据。
(i)使用与第3章习题4一样的模型,表述并检验虚拟假设:在其他条件不变的情况下,法学院排名对起薪中位数没有影响。
(ii)新生年级的学生特征(即LSAT和GPA) 对解释salary而言是个别或联合显著的吗?
(iii)检验是否要在方程中引入入学年级的规模(clsize) 和教职工的规(faculty) ; 只进行一个检验。(注意解释clsize和faculty的缺失数据。)
(iv)还有哪些因素可能影响到法学院排名,但又没有包括在薪水回归中?
在习题3.4中,我们估计了方程
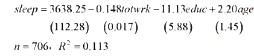
其中的标准误是我们现在才同估计值一并给出的。
(i)相对于一个双侧对立假设,是educ还是age在5%的水平上是个别显著的?给出你的计算。
(ii)从方程中去掉educ和age,则得到
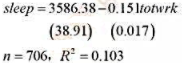
在5%的显著性水平上,educ和age在原方程中是联合显著的吗?说明你所给答案的理由。
(iii)在模型中包括educ和age,是否显著影响所估计的睡眠和工作之间的替换关系?
(iv)假设睡眠方程含有异方差性。这对第(i)和(ii)部分计算的检验意味着什么?
利用CHARITY.RAW中的数据回答如下问题
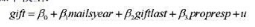
(i)用普通最小二乘法估计如下模型:
按照通常的方式报告估计方程,包括样本容量和R²。其R²与不使用giftlast和propresp的简单回归所得到的R²相比如何?
(ii)解释mailsyear的系数,它比对应的简单回归系数更大还是更小?
(iii)解释propresp的系数,千万要注意propresp的度量单位。
(iv)现在,在这个方程中增加变量avggif。这将对mailsyear的估计效应造成什么样的影响?
(v)在第(iv)部分的方程中,giftlast的系数有何变化?你认为这是怎么回事?
本题利用MEAP93.RAW中的数据。
(i) 估计模型math10=β0+β1log(expend)+β2Inchprg+u,并按照通常的方式报告估计方程,包括样本容量和R2。斜率系数的符号与你的预期一致吗?请加以解释。
(ii)你如何理解第(i)部分中估计出来的截距?特别是,令两个解释变量都等于零说得过去吗?[提示:记住log(1)=0。]
(i)现在做math10对log(expend)的简单回归, 并将斜率系数与第(i)部分中得到的估计值进行比较。与第(i)部分中的结果相比,这里估计出来的支出效应是更大还是更小?
(iv)求山lexpend=log(expend)与Inchprg之间的相关系数。你认为其符号合理吗?
(v)利用第(iv)部分的结果来解释你在第(iii)部分中得到的结论。
















