 题目内容
(请给出正确答案)
题目内容
(请给出正确答案)
[单选题]
假设对给定数据应用了Logistic回归模型,并获得了训练精度X和测试精度Y。现在要在同一数据中添加一些新特征,以下哪些是错误的选项。注:假设剩余参数相同。
A.训练精度提高
B.训练准确度提高或保持不变
C.测试精度提高或保持不变
查看答案

 如果结果不匹配,请 联系老师 获取答案
题目内容
(请给出正确答案)
如果结果不匹配,请 联系老师 获取答案
题目内容
(请给出正确答案)
A.训练精度提高
B.训练准确度提高或保持不变
C.测试精度提高或保持不变
如果结果不匹配,请 联系老师 获取答案
 更多“假设对给定数据应用了Logistic回归模型,并获得了训练精…”相关的问题
更多“假设对给定数据应用了Logistic回归模型,并获得了训练精…”相关的问题
A.朴素贝叶斯(NaiveBayes,NB)
B.Logistic回归(LogisticRegression,LR)
C.支持向量机(SupportVectorMachine,SVM)
D.决策树(DecisionTree,DT)
以y=a+bx对给定数据进行回归处理,并以此作为未来变化规律的市场预测方法是()
A.回归线方法
B.二次曲线法
C.指数平滑法
D.抛物线法
A.Logistic回归更关注预测值接近观测值(0或1)的程度
B.Logistic回归模型的参数估计使用普通最小乘法(OLS)
C.上手Logistic回归更关注正确预测的频率以及模型能否有效减少误差
D.利用SPSS进行Logistic回归时,输出结果中的Cox-Snell和Nagelkerke值说明了自变量解释因变量变异的比例
E.Logistic回归解释了自变量和因变量概率取值之间的关系
使用PHILLIPS.RAW中的数据。
(i)教材例11.5中,我们估计了如下形式的附加预期的菲利普斯曲线:
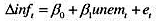
其中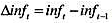 。用OLS估计该方程时,我们假定供给冲击et与unemt不相关。如果这是错误的,关于βt的OLS估计量可做什么解释?
。用OLS估计该方程时,我们假定供给冲击et与unemt不相关。如果这是错误的,关于βt的OLS估计量可做什么解释?
(ii)假定et在给定所有过去信息的条件下是不可预期的:
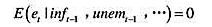
解释为什么这使得unemt-1成为unemt的一个好的Ⅳ候选者。
(iii)将unemt对unemt-1做回归。unemt与unemt-1是否显著相关?
(iv)用Ⅳ估计附加预期的菲利普斯曲线。以通常形式报告结果,并将之与教材例11.5中的OLS估计值进行比较。
)与每个学生的平均支出(expend) 之间的关系。
(Ⅰ)就多花一美元对通过率的影响而言,你认为具有恒定不变的影响合适呢,还是这种影响越来越小更合适?请加以解释。
(Ⅱ) 在总体模型math10=β0+β1log(expend)+u中,证明民β1/10表示expend提高10%导致math10改变的百分数。
(II) 利用MEAP 93.RAW中的数据, 估计(Ⅱ) 中的模型.按照通常的方式报告估计方程, 包括样本容量和及R2。
(Ⅳ)支出的估计影响有多大?也就是说, 如果支出提高10%, 估计math10会提高多少个百分点?
(Ⅴ)有人担心这个回归分析可能得到math10的拟合值会超过100。为什么在这个数据集中不必担心这个问题?

















