 题目内容
(请给出正确答案)
题目内容
(请给出正确答案)
[多选题]
我们为什么要增加数据/图表的对比?()
A.有了相互比较,教师才有动力
B.领导要求教师,相互之间要对比数据
C.只有数据对比后,才能发现异常数据
D.数据只有对比,才能展先数据的价值
查看答案

 如果结果不匹配,请 联系老师 获取答案
题目内容
(请给出正确答案)
如果结果不匹配,请 联系老师 获取答案
题目内容
(请给出正确答案)
A.有了相互比较,教师才有动力
B.领导要求教师,相互之间要对比数据
C.只有数据对比后,才能发现异常数据
D.数据只有对比,才能展先数据的价值
如果结果不匹配,请 联系老师 获取答案
 更多“我们为什么要增加数据/图表的对比?()”相关的问题
更多“我们为什么要增加数据/图表的对比?()”相关的问题
A.单一的数字只是一个“数值”,意义不大
B.数据只有靠积累和沉淀才能发现问题,体现价值
C.数据积累是所有教学大数据软件的一个重要功能,所以要注重
D.数据积累操作比较简单,所以老师需要注重
A.修改工作表中的数据,图表中的数据系列不会修改
B.以上三项不正确
C.删除工作表中的数据,图表中的数据系列不会删除
D.增加工作表中的数据,图表中的数据系列不会增加
利用WAGEPAN中数据。
(i)利用混合最小二乘法(pooledOLS)估计一个log(ag为被解释变量的方程。以educ,black,exper,married,union以及一系列时间虚拟变量(以1980年为基年)为可解释变量,解释及讨论变量married和union的系数。
(ii)解释为什么通常(i)中标准误总是偏小。算出关于married和union两个变量对自相关和异方差一稳健的标准误。
(iii)现在对变量lwage,exper,married和union进行一阶差分。(不随时间改变的变量educ,black和hisp被排除在这个估计之外,exper也是,因为它总是随着年份增加。)注意排除首年即1980年的一阶差分,因为不存在更早的年份。
(iv)就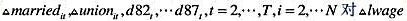 作回归分析,确保包括一个常数项和一个从1982年到1987年的时间虚拟变量。算出Δmarried和Δunion的系数和标准误。
作回归分析,确保包括一个常数项和一个从1982年到1987年的时间虚拟变量。算出Δmarried和Δunion的系数和标准误。
(v)对比婚姻状况和工会保费的估计水平及其一阶差分估计,并作相应评论。
为什么会发生这种情况呢?在(b)中,你花在X上的钱要多于花在Y上的钱。在(c)中,x的价格下降类似于你的收入大大增加;事实上,你的总效用也从原先的600尤特尔增加到了(620/664/670/674)尤特尔。为什么呢?因为你拥有了更多的收入来购买更多的X和更多的Y。 当X的价格下降时,有两种效应开始对你购买X和Y的欲望起作用。如果X和Y为替代品,你会购买(更多的/更少的)Y和更多的X。但起相反作用的是之前我们讨论的收入效应,这驱使你购买(更多的/更少的)X和(更多的/更少的)Y。在这个例子中,收入效应的作用大于替代效应。如果X和Y为替代程度很高,那么你购买Y的数量应该减少而不是增加了。

















