 题目内容
(请给出正确答案)
题目内容
(请给出正确答案)
[单选题]
一个数据分布的锋度系数为()时,该数据分布曲线分布显得最瘦高、尖削。
A.-1.05
B.-0.5
C.0
D.2
查看答案

 如果结果不匹配,请 联系老师 获取答案
题目内容
(请给出正确答案)
如果结果不匹配,请 联系老师 获取答案
题目内容
(请给出正确答案)
A.-1.05
B.-0.5
C.0
D.2
如果结果不匹配,请 联系老师 获取答案
 更多“一个数据分布的锋度系数为()时,该数据分布曲线分布显得最瘦高…”相关的问题
更多“一个数据分布的锋度系数为()时,该数据分布曲线分布显得最瘦高…”相关的问题
110℃时,水(1)-正丁醇(2)液液平衡数据为x'1=0.9788,x"2=0.6759。试计算汽相的组成y及总压p。
已知饱和蒸气压为:
活度系数采用Van Laar方程计算:
其中A、B为活度系数方程参数。
A.交叉验证法先将数据集划分为k个大小相似的互斥子集
B.交叉验证法将数据集划分成的k个子集应尽可能保持数据分布的一致性
C.通常把交叉验证法称为k折交叉验证
D.假定数据集D中包含m个样本,若令交叉验证法中的系数k=m,则得到了交叉验证法的一个特例:自助法
A.数据库的集中
B.数据的水平分布
C.数据的垂直分布
D.数据的复制
利用WAGEPAN中数据。
(i)利用混合最小二乘法(pooledOLS)估计一个log(ag为被解释变量的方程。以educ,black,exper,married,union以及一系列时间虚拟变量(以1980年为基年)为可解释变量,解释及讨论变量married和union的系数。
(ii)解释为什么通常(i)中标准误总是偏小。算出关于married和union两个变量对自相关和异方差一稳健的标准误。
(iii)现在对变量lwage,exper,married和union进行一阶差分。(不随时间改变的变量educ,black和hisp被排除在这个估计之外,exper也是,因为它总是随着年份增加。)注意排除首年即1980年的一阶差分,因为不存在更早的年份。
(iv)就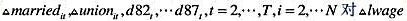 作回归分析,确保包括一个常数项和一个从1982年到1987年的时间虚拟变量。算出Δmarried和Δunion的系数和标准误。
作回归分析,确保包括一个常数项和一个从1982年到1987年的时间虚拟变量。算出Δmarried和Δunion的系数和标准误。
(v)对比婚姻状况和工会保费的估计水平及其一阶差分估计,并作相应评论。


















